Refactoring Gibbon
Open Source, Web DevelopmentThe Challenge
Gibbon was created by Ross Parker and has been in development at ICHK since 2010. The codebase is huge and quite feature-rich, so naturally over the years it has also accumulated some legacy code. As my work on Gibbon has evolved from small fixes to whole features, I’ve also been leading the efforts to refactor and modernize the codebase.
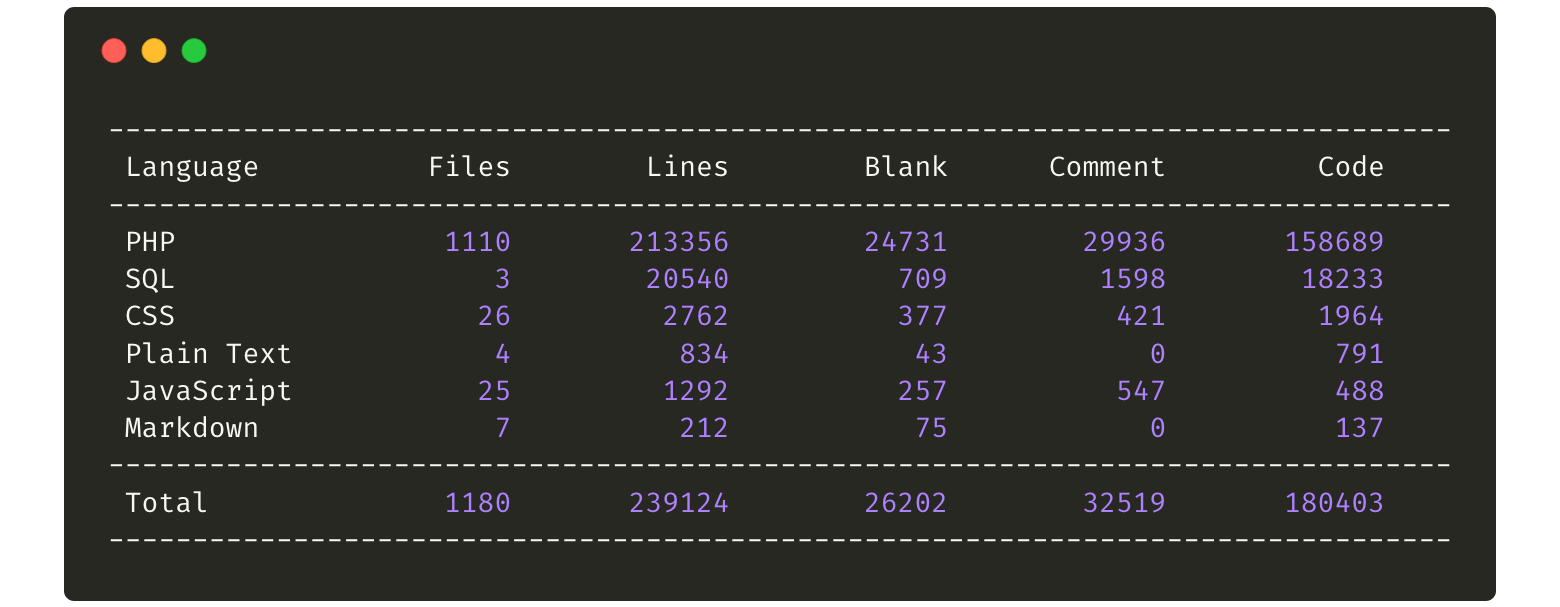
There’s a lot of code! Gibbon is written in PHP with a MySQL database. It is built with a modular structure, currently with twenty-three core modules that cover everything from attendance to markbooks, student data, lesson planning, and school activities.
Why Refactor?

PHP has come a long way since Gibbon was started.
It continues to develop into a modern language with the addition of object-oriented structures, namespacing, test frameworks, dependency management, and standards set by the PHP FIG.
Gibbon has come a long way too!
It started with a few core features, and evolved over the years into a full school platform. This sustainability is due largely to the pragmatic approach Ross has taken over the years; setting regular release cycles, developing incrementally, and placing a strong focus on maintaining the stability of the platform for all the schools who depend on it.
Certainly, throwing everything out and rewriting from scratch isn’t an option! There is an increasing a number of schools using Gibbon (including the school I work for), and the logic inside the code represents wisdom learned from creating and refining features over several years.
Refactoring then becomes a natural part of the codebase’s lifecycle. On Legacy Code Rocks, a favourite podcast of mine, they describe this process as Menders vs. Makers.
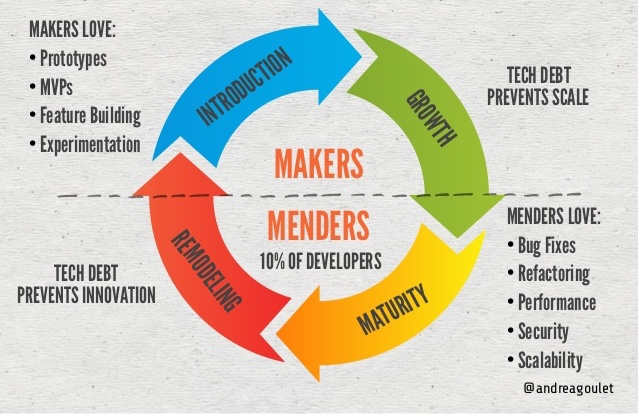
Mending … is more like the show “This Old House”. There’s often a very good reason that the existing structure should stay, but to update it requires digging in, knocking down walls, and sometimes dealing with the unexpected things you find. Angrea Goulet, Founder/CEO of Corgibytes
Refactoring Goals
Once we know why we want to refactor, the next question is how.
Above all we want to keep the whole thing running while we rewire the code, so the answer is to set some goals to incrementally refactor the codebase—piece by piece—to introduce all this fun, modern software architecture at a reasonable pace.
Deleting Code
As a developer, it’s incredibly satisfying to delete code. Especially if it all still runs afterwards!
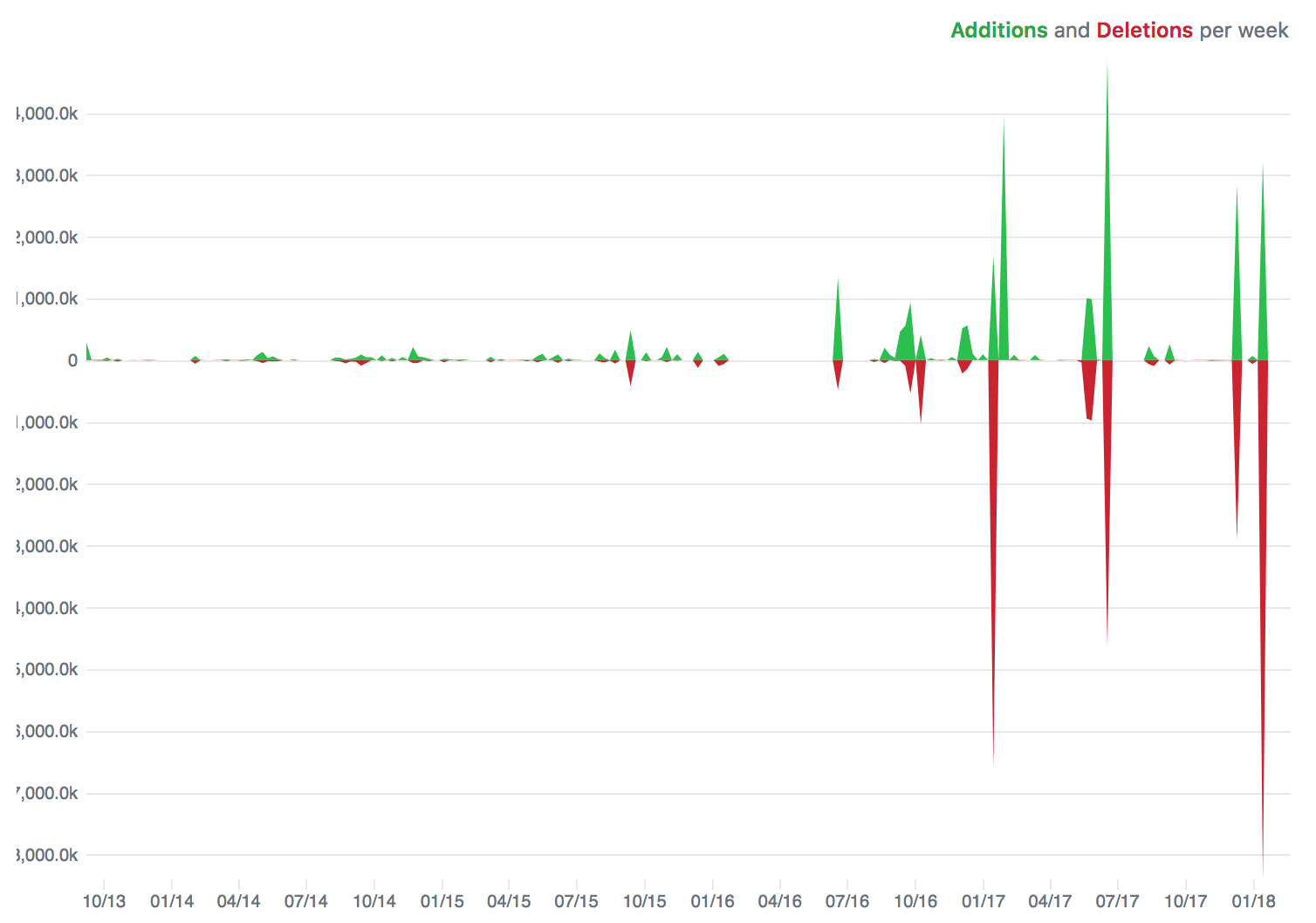
This is an example of the code frequency graph from GitHub, early on in our refactoring efforts. My favourite part of the graph is the red spikes on the bottom, where I get to delete the legacy code and replace it with something more streamlined.
What to delete?
Our first refactoring goal is to identify areas in the the codebase with the most repeated code. Despite a tempting array of modern ideas and tools to implement, slimming down the codebase has to be our top priority.
It’s a big application, so there’s a lot of CRUD happening (not that kind of crud). Two of the most common areas of repeated code are: the forms for user input, and the tables to display records.
Here’s an example of some original code. It’s very procedural, with lots of HTML, PHP and Javascript all mixed together.
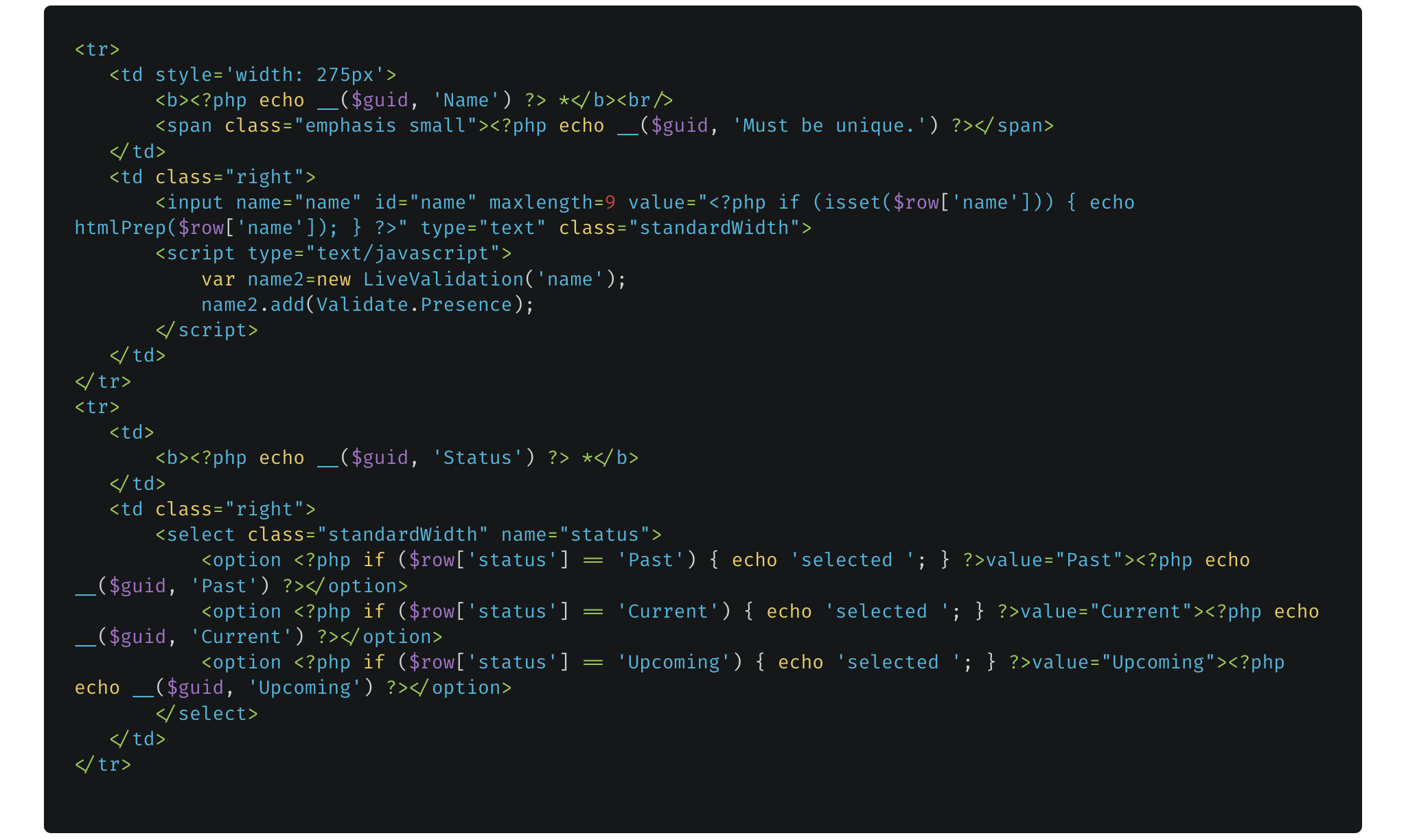
And the resulting object-oriented PHP, which accomplishes the same thing.
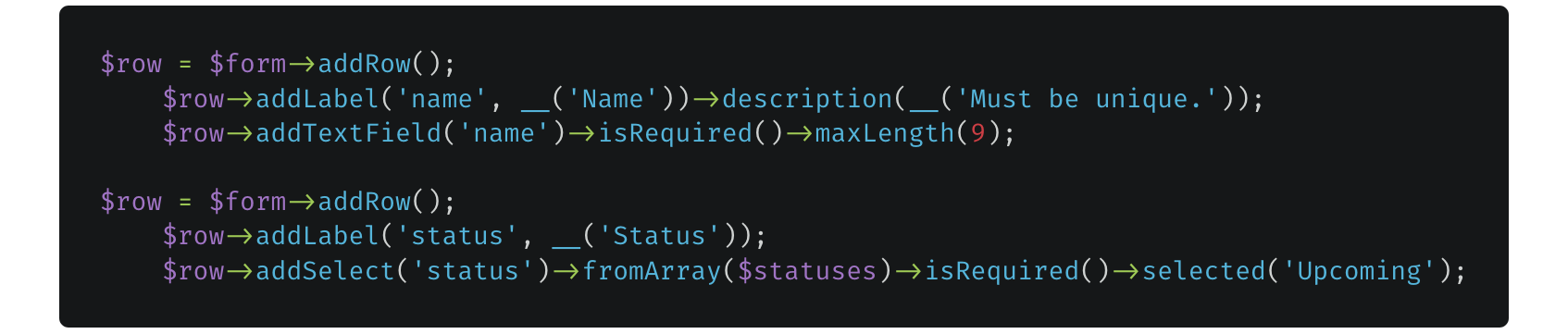
Automated Tests
Legacy code can be defined in a lot of different ways. Michael Feathers’ definition is simply “code without tests”. I think as a developer, once you dive into a codebase it can just feel legacy, and in some cases it may even smell legacy.
This leads to the question:
How do you refactor code that doesn’t have tests?
The simplest answer: add tests. Which leads to the next question:
How to you test legacy code?
That’s the conundrum! In our case, much of the code isn’t object-oriented yet, so we can’t just start writing unit tests. We needed to find a different way to introduce test coverage for the codebase.

My solution is to write acceptance tests with Codeception. These use a very simple syntax, and let us simulate what a user can see and do in Gibbon.
This gives us a new refactoring workflow:
Write the Test + Refactor + Run the Test
It’s a little backwards for Test-Driven Development! But it gives a developer the much-needed confidence to start rewriting more and more of the legacy code.


With some tests in place, I could introduce some continuous integration tools using Travis CI to help us run the tests each time a pull request or commit is added to the codebase.
Systematic Change
When you encounter a legacy codebase, it’s tempting to roll-up your sleeves, reach for the rubber gloves—maybe a hazmat suit—and just dive in to start fixing things. In a large codebase, especially one without test coverage, this can be disastrous.
We want to avoid this outcome! So our goal is to be very intentional and systematic about the code that gets changed; to pick one thread and follow it. This means thinking wide instead of deep: make one change, then repeat it throughout the codebase, and test the result thoroughly.
Sometimes it means resisting that temptation to rewrite a chunk of code, and trusting that eventually all the pieces will come together.
What’s Next?
Trimming down the repeated code and introducing test coverage is just the start. As we continue to refactor Gibbon, we’re introducing many of the hallmarks of the modern PHP ecosystem. For each change, we’ll use the same workflow outlined above: be systematic, write tests, delete code.
A key to this effort has also been to refactor Gibbon’s documentation at the same time. Our amazing developer community is growing, so we’ve updated the docs to be open-source and community-driven, with the aim to support new developers looking to join the project and possibly even help with these refactoring efforts.
Inspiration





Further Reading:
- Let’s Define Legacy Code
- To rewrite or to remodel? That is the question.
- Developer Differences: Makers vs Menders
- Communication Is Just As Important As Code
This topic was originally co-presented with Ross at the February 2018 Codeaholics Meetup and at HKOSCon June 2018. This version has more words, and sadly less of the humour from the first talk.